Training a CNN for MNIST on Google Cloud ML
In this post I am going to describe how to setup a tensorflow graph to run on the Google Cloud.
- Sign up for the 12 months 300$ trial account
- Create a new project and enable the google compute engine and the cloud machine learning apis
- Open the cloud shell and set the new project as active with
gcloud config set project <project_id> - check that the new setup is empty with
gcloud ml-engine models listreturn “Listed 0 items.”
Okay we are good to go. Let’s fetch the a tensorflow project which contains code that can be deployed to the google cloud platform (it uses the same CNN structure which I used for my tensorflow example).
git clone https://github.com/GoogleCloudPlatform/cloudml-dist-mnist-example and cd into it.
Now run we use a script from this repo to download MNIST to the tmp folder: ./scripts/create_records.py
For convenience we store the project_id in an env var: PROJECT_ID=$(gcloud config list project --format "value(core.project)") and create a name from that for our bucket: BUCKET="${PROJECT_ID}-ml".
Now we create bucket in the US: gsutil mb -c regional -l us-central1 gs://${BUCKET}
The next step is to copy the training and test data to the bucket:
gsutil cp /tmp/data/train.tfrecords gs://${BUCKET}/data/
gsutil cp /tmp/data/test.tfrecords gs://${BUCKET}/data/
Create a Cloud Machine Learning job:
$ JOB_ID="${USER}_$(date +%Y%m%d_%H%M%S)"
$ gcloud ml-engine jobs submit training ${JOB_ID} \
--package-path trainer \
--module-name trainer.task \
--staging-bucket gs://${BUCKET} \
--job-dir gs://${BUCKET}/${JOB_ID} \
--runtime-version 1.2 \
--region us-central1 \
--config config/config.yaml \
-- \
--data_dir gs://${BUCKET}/data \
--output_dir gs://${BUCKET}/${JOB_ID} \
--train_steps 10000
The upper part of the arguments is necessary to define the job and the args under the blank “–” are custom settings for the model of this repository.
Now we created a job by name $JOB_ID. We can check its status by running gcloud ml-engine jobs describe ${JOB_ID}. We see that is automatically started and is running now…
In the UI (https://console.cloud.google.com/mlengine/jobs) we can see out job now.
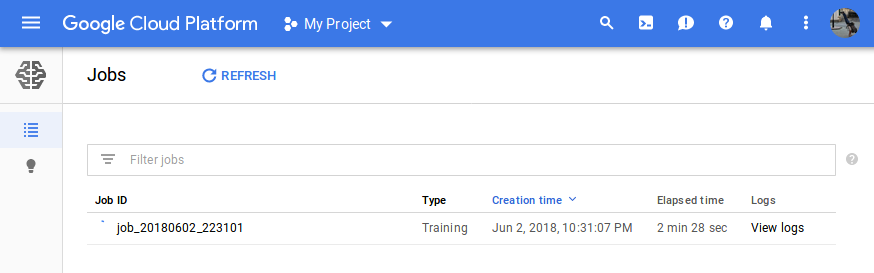
With 10.000 training steps the job ran for 12 min 36 sec (in the tensorboard only 7 min 20 sec are displayed).
The trained model is stored in a location on the bucket which can be found like this:
gsutil ls gs://${BUCKET}/${JOB_NAME}/export/Servo | tail -1
Of course we would like to view the tensorboard for the model:
Let’s start it: tensorboard --port 8080 --logdir gs://${BUCKET}/${JOB_NAME}
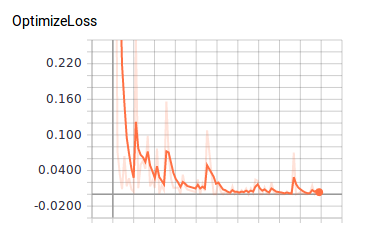
The next thing to do is to host the model for predictions:
MODEL_NAME=MNIST
gcloud ml-engine models create --regions us-central1 ${MODEL_NAME}
VERSION_NAME=v1
ORIGIN=$(gsutil ls gs://${BUCKET}/${JOB_NAME}/export/Servo | tail -1)
gcloud ml-engine versions create \
--origin ${ORIGIN} \
--model ${MODEL_NAME} \
${VERSION_NAME}
gcloud ml-engine versions set-default --model ${MODEL_NAME} ${VERSION_NAME}
The repo contains a test script which creates test images and stores them in “request.json”:
./scripts/make_request.py
Now we can interact with google-ml to make a prediction:
gcloud ml-engine predict --model ${MODEL_NAME} --json-instances request.json
It returns:
CLASSES PROBABILITIES
7 [4.5843234630944225e-18, 6.193453955997711e-17, 3.8354377123635806e-16, 3.148550425710454e-15, 7.259249176097093e-16, 5.707018252740535e-20, 2.0105221419381174e-23, 1.0, 8.201609924387802e-18, 9.082074454741951e-15]
...
Which does only help to see that something is responding.
To further check our model we can play around with a jupyter notebook which allows us to draw numbers and predict them with the trained model. To enable running special notebooks in the google cloud you have to enable the “Cloud Source Repositories API”.
datalab create mnist-datalab --zone us-central1-a
Once it is ready you can open the datalab (switch preview port from 8080 to 8081) and create a new notebook.
Run the following bash code in the first cell of the new notebook to download a cool new notebook.
%%bash
wget https://raw.githubusercontent.com/GoogleCloudPlatform/cloudml-dist-mnist-example/master/notebooks/Online%20prediction%20example.ipynb
cat Online\ prediction\ example.ipynb > Untitled\ Notebook.ipynb
Reload.
The notebook contains a javascript canvas drawing tool!
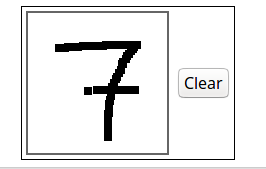
Now let’s run from the next cell… And believe it or not, the seven was predicted correctly!
CLASSES PROBABILITIES
7 [5.11849281784098e-19, 9.276371107347879e-15, 2.3685901240355633e-08, 7.94676564136454e-12, 2.611663272797382e-12, 5.828779885143194e-19, 1.2706371472628209e-20, 1.0, 2.9332114034344755e-18, 1.254095704237082e-13]
Talking about performance
While I am drawing numbers and they are recognized my laptop is still busy on its four cores to train the same model with 20.000 training steps.
Let’s see whether I can train the model again with 20.000 training steps in the gcloud.
First of all I am going to delete this project and create a new one.
Before running the job I am going to change “config/config.yaml” from STANDARD_1 to PREMIUM_1 (see a list of options here). This means that there will be more parameter servers and more workers. So actually what I am doing is just throwing more resources at the the same code. Let’s see whether it reduces the time to train.
The previous CNN had only 10.000 training steps and it took 12 minutes. So with the STANDARD tier it should take 24 minutes to train it. The exception is that the PREMIUM tier will be faster…
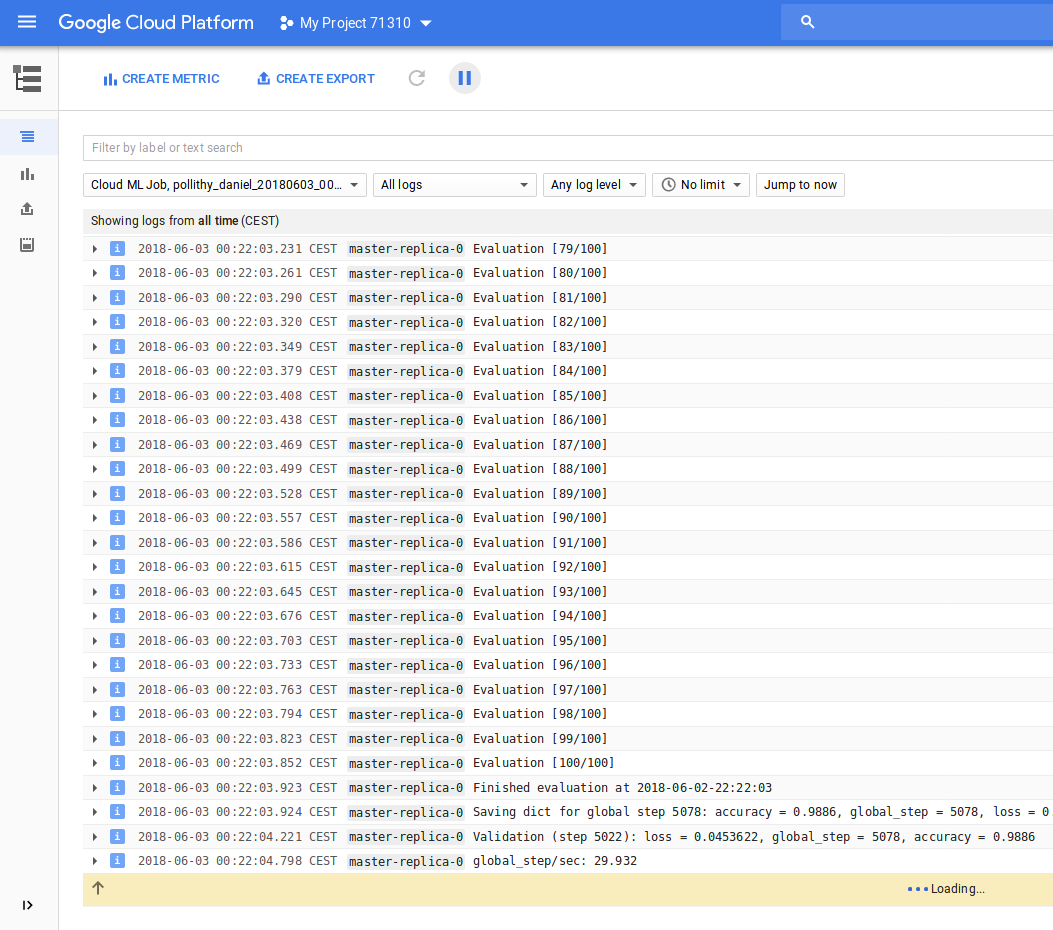
After 16 minutes and 17 seconds the job was done. And it consumed ten times more ML units (9.92) than the STANDARD_1 tier.
My quad core laptop was calculating 101 minutes. So the PREMIUM_1 took only 17% of the time my laptop needed.
https://cloud.google.com/ml-engine/docs/tensorflow/distributed-tensorflow-mnist-cloud-datalab
https://cloud.google.com/ml-engine/reference/rest/v1/projects.jobs#scaletier
https://cloud.google.com/ml-engine/docs/tensorflow/regions
