Review of the video course
When looking up resources on how to get a good overview of neural networks for computer vision you almost always get pointed to the youtube videos of the CS231n course held at Stanford.
I watched the videos from 2016/2017 and did 2/3 of the assignments. The following is just a general comment on how the lecture is presented, a list of the youtube videos and more.
Surrounding
The course is held by Andrej Karphathy (10 lectures), Justin Johnson (3 lectures) and Fei-Fei Li (first lecture) who were part of the Stanford Vision and Learning Lab - SVL at that time. The last lecture was given by Jeff Dean who talked about Neural Networks at Google. The SVL was known for hosting a computer vision challenge called “the imagenet competition”.
The playlist of cs231n winter 2016 can be found on youtube and the course notes are hosted on cs231n.github.io.

(The pictures of the collage were taken from youtube screenshots)
Structure and content
There are three assignments (which are online available). The students also had to write a midterm which is not online. At the end of the class a project had to be presented.
The class explains different problems of computer vision, like:
- Image classification: “Does the picture show a dog or a cat?”
- Semantic segmentation and instance segmentation: “Which part of the image contains trees?”
- Image captioning: “Describe the image with word!”
Within this frame it is first shown a little bit how these problems were used to be solved before the “rise of deep learning”. And then the lectures get quickly to the point on how neural networks work, how they can be trained and especially how they are programmed.
And that is what the first assignments are all about: Building your own python versions of neural nets, softmax, sgd, cross-validation, backpropagation and regularizations.
But the performance of the network you train to classify images is “only” at 60%.
Then they introduce the convolutional neural networks and within the second assignment you can see, how the performance rises although the computational time got significantly shorter.
The lectures after that are about deep learning frameworks (like Theano, torch, caffe, tensorflow), recurrent neural networks, segmentation of images, detection in videos and unsupervised learning.
In general it feels like you get a good understanding of the things because you have to implement parts of them in python. Although especially figuring out the backward pass in the computational graph was/is difficult for me.
The later parts like working with videos and segmentation are a good introduction but it is kept to the viewer to find a new source of learning because it is not covered in the assignment.
My personal opinion is that the intuitions, interactive javascript demos and good exercises are the most valuable parts of the course. The second half of the course contains more recent works so the didactic is not as advanced and sometimes it feels more like a paper discussion group (which is also nice).
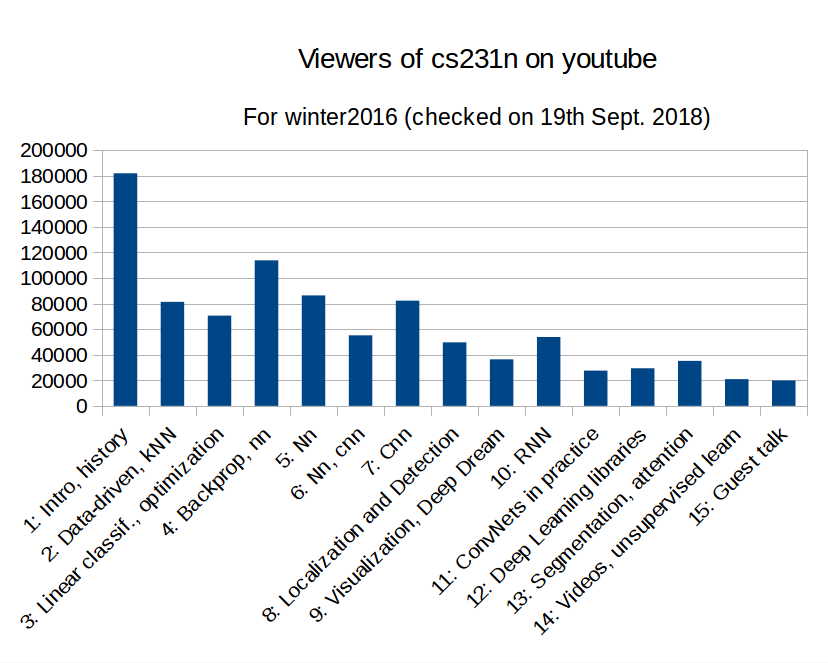
How many viewers
I enjoyed watching these videos and the following diagram shows how many youtube viewers felt the same, distributed over the videos of winter 2016.